4.4 Napping analysis (M9a)
4.4.1 Method description
The Napping allows you to look for sensory differences between products. Differences are on global sensory characteristics and should be complemented with a verbalisation task to ease the understanding of the differences. It offers greater flexibility, as no trained panel is needed.
Two tasks are done in a Napping:
- The sorting task: each taster is asked to position the whole set of products on a sheet of blank paper (a tablecloth) according to their similarities/dissimilarities. Thus, two products are close if they are perceived as similar or, on the contrary, distant from each other if they are perceived as different. Each taster uses his/her own criteria.
- The verbalisation task: After performing the napping task, the panellists are asked to describe the products by writing one or two sensory descriptors that characterize each group of products on the map.
Panels should be composed from 12 to 25 tasters according to the judge’s experience with the product and to the objective of the experiment. For example ten farmers-bakers should be enough to have reliable results as they are used to eat and taste bread. In case of consumers, a panel of twenty could be more adapted.
No more than ten products should be evaluate simultaneously. A random, three-digit code should be assigned to each sample. Samples are presented simultaneously and the assessors can taste as much as they need. Napping data lead to a quantitative table. The rows are the products. This table presents the number of panellists (\(i\)) sets (one set for each panellist) of two columns corresponding to the horizontal and vertical coordinate (\(X\), \(Y\)). Two columns correspond to each subject (i.e. person that taste) \(j\): the X-coordinate (\(X_j\)) and the Y-coordinate (\(Y_j\)) for each product.
Sensory descriptors are coded through a “products x words” frequency table. First a contingency table counting the number that each descriptor has been used to describe each product is created. Then this contingency table is transformed in frequencies so that the “word frequency” is a qualitative variables with the number of words cited as modalities.
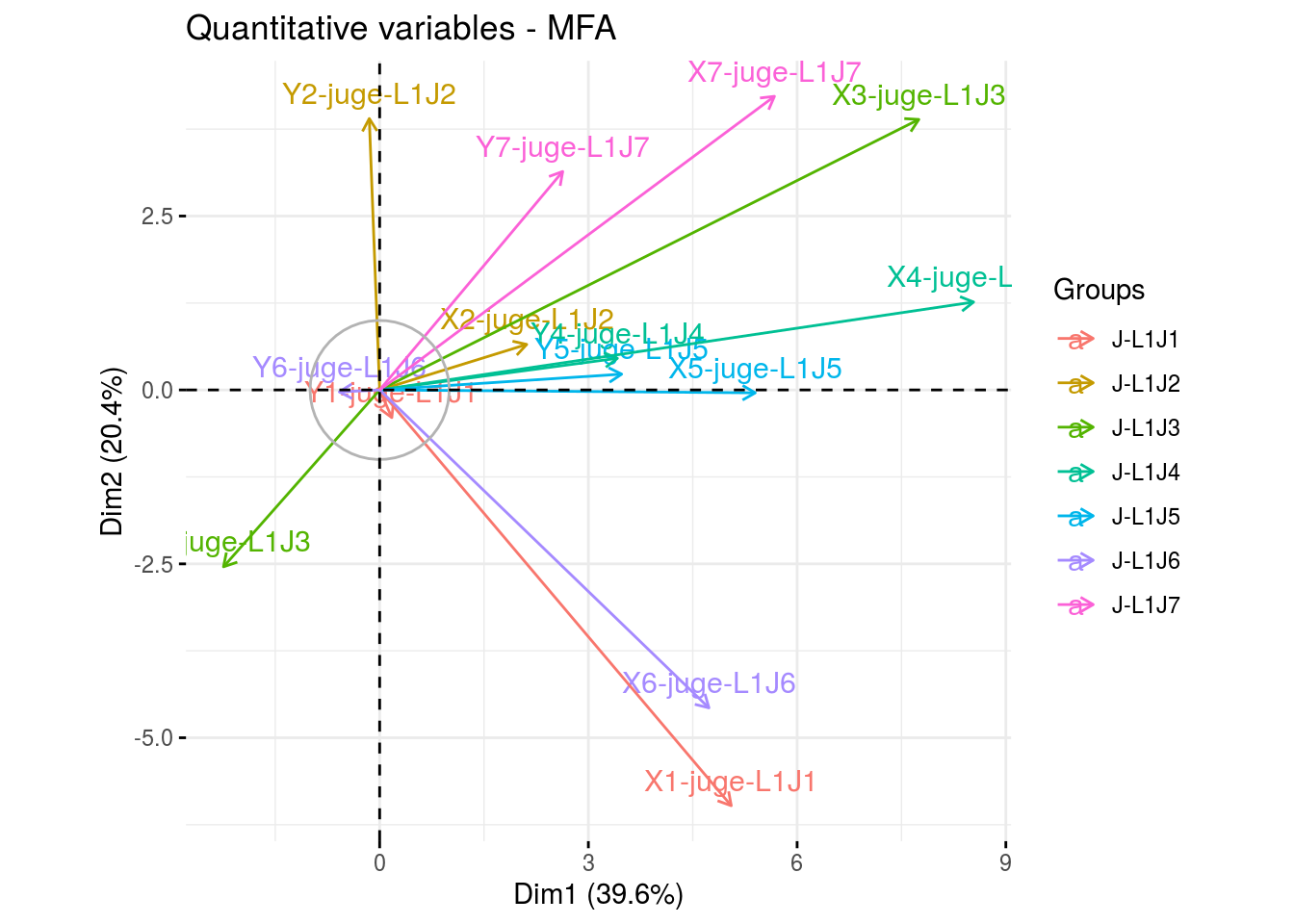
To analyse this kind of data, a Multiple Factor Analysis (MFA) should be performed. Each subject constitute a group of two un-standardised variables. The MFA led to a synthesis of the panellist’s tablecloth. Two products are close if all judges consider them close on the napping. The more the two first components of MFA explain the original variability, the more the judges are in agreement.
The frequency table crossing products and word frequency is considered as a set of supplementary variables: they do not intervene in the axes construction but their correlation with the factors of MFA are calculated and represented as in usual PCA.
4.4.2 Steps with PPBstats
For hedonic analysis, you can follow these steps (Figure 4.2):
- Format the data with
format_data_PPBstats() - Describe the data with
plot() - Run the model with
model_napping() - Check model outputs with graphs to know if you can continue the analysis with
check_model() - Format data for multivariate analysis with
biplot_dataand visualise it withplot()
4.4.3 Format the data
data(data_napping)
head(data_napping)## juges X Y descriptors germplasm location
## 1 L1J1 7.61970 15.2778 peau_épaisse;sans intérêt;;; germ-2 loc-4
## 2 L1J1 24.15010 15.4831 agréable;équilibrée;parfumée;; germ-8 loc-4
## 3 L1J1 24.38950 15.1427 agréable;équilibrée;parfumée;; germ-10 loc-4
## 4 L1J1 7.73941 15.1076 peau_épaisse;sans intérêt;;; germ-7 loc-4
## 5 L1J1 24.50820 14.8881 agréable;équilibrée;parfumée;; germ-5 loc-4
## 6 L1J1 7.73648 14.8546 peau_épaisse;sans intérêt;;; germ-6 loc-4The data frame has the following columns: juges, X, Y, descriptors, germplasm, location. The descriptors must be separated by “;”. Any other column can be added as supplementary variables.
Then, you must format your data with format_data_PPBstats() and type = "data_organo_napping".
Argument threshold can be set in order to keep only descriptors that have been cited several time.
For exemple with threshold = 2, on ly descriptors cited at least twice are kept.
data_napping = format_data_PPBstats(data_napping, type = "data_organo_napping", threshold = 2)## The following descriptors have been remove because there were less or equal to 2 occurences : arôme_tomate, arôme_végétal, mauvaise, sans jus## data has been formated for PPBstats functions.names(data_napping)## [1] "data" "descriptors"data_napping is a list of three elements :
- data the data formated to run the anova and the multivariate analysis
head(data_napping$data)## X1-juge-L1J1 Y1-juge-L1J1 X2-juge-L1J2 Y2-juge-L1J2
## loc-4:germ-10 24.38950 15.14270 18.53270 3.9187
## loc-4:germ-2 7.61970 15.27780 11.37260 18.9406
## loc-4:germ-3 11.64060 7.00228 6.27019 17.0350
## loc-4:germ-4 7.79372 14.54460 23.62950 18.1938
## loc-4:germ-5 24.50820 14.88810 15.39790 12.4406
## loc-4:germ-6 7.73648 14.85460 17.55090 17.5473
## X3-juge-L1J3 Y3-juge-L1J3 X4-juge-L1J4 Y4-juge-L1J4
## loc-4:germ-10 26.8953 3.75490 24.26340 13.48410
## loc-4:germ-2 26.7636 4.09963 24.80630 16.02890
## loc-4:germ-3 26.8551 4.22765 13.62570 10.72710
## loc-4:germ-4 17.4600 8.56266 13.41170 11.02890
## loc-4:germ-5 26.8956 3.62606 24.47550 13.29670
## loc-4:germ-6 10.5918 7.70753 4.11214 4.01245
## X5-juge-L1J5 Y5-juge-L1J5 X6-juge-L1J6 Y6-juge-L1J6
## loc-4:germ-10 18.43640 14.65120 24.61340 6.72938
## loc-4:germ-2 20.16100 15.64430 11.01970 8.67583
## loc-4:germ-3 7.60143 15.09500 16.93540 5.15873
## loc-4:germ-4 7.29285 18.64860 3.97412 7.57718
## loc-4:germ-5 24.14130 17.18980 11.27140 9.42970
## loc-4:germ-6 4.04596 2.31195 3.97323 7.97040
## X7-juge-L1J7 Y7-juge-L1J7 acide acidulée agréable aqueuse
## loc-4:germ-10 24.96780 17.57220 0.00 0.125 0.25 0.0000000
## loc-4:germ-2 27.35150 18.71840 0.00 0.000 0.00 0.0000000
## loc-4:germ-3 12.00590 11.96920 0.50 0.250 0.00 0.0000000
## loc-4:germ-4 6.38053 6.29118 0.25 0.000 0.00 0.0000000
## loc-4:germ-5 25.73110 15.94830 0.00 0.000 0.25 0.0000000
## loc-4:germ-6 11.89530 9.95286 0.00 0.125 0.00 0.3333333
## aromatique douce équilibrée fade farineuse fibreuse
## loc-4:germ-10 0.2 0.250 0.1666667 0.00000000 0.1428571 0.0000000
## loc-4:germ-2 0.3 0.000 0.0000000 0.00000000 0.0000000 0.0000000
## loc-4:germ-3 0.1 0.125 0.0000000 0.07692308 0.0000000 0.0000000
## loc-4:germ-4 0.0 0.000 0.0000000 0.15384615 0.2857143 0.0000000
## loc-4:germ-5 0.2 0.125 0.3333333 0.07692308 0.0000000 0.0000000
## loc-4:germ-6 0.1 0.125 0.0000000 0.15384615 0.1428571 0.3333333
## fondante fruitée gouteuse juteuse parfumée
## loc-4:germ-10 0.09090909 0.0000000 0.25000000 0.125 0.25
## loc-4:germ-2 0.18181818 0.0000000 0.25000000 0.250 0.00
## loc-4:germ-3 0.18181818 0.0000000 0.08333333 0.125 0.00
## loc-4:germ-4 0.18181818 0.0000000 0.00000000 0.000 0.00
## loc-4:germ-5 0.09090909 0.3333333 0.25000000 0.250 0.25
## loc-4:germ-6 0.00000000 0.0000000 0.00000000 0.125 0.00
## peau_épaisse raffraichissante sans intérêt sucrée
## loc-4:germ-10 0.05882353 0.3333333 0.0000000 0.23529412
## loc-4:germ-2 0.11764706 0.3333333 0.1666667 0.23529412
## loc-4:germ-3 0.11764706 0.0000000 0.0000000 0.05882353
## loc-4:germ-4 0.11764706 0.0000000 0.1666667 0.00000000
## loc-4:germ-5 0.11764706 0.3333333 0.0000000 0.23529412
## loc-4:germ-6 0.23529412 0.0000000 0.1666667 0.00000000
## sample
## loc-4:germ-10 loc-4:germ-10
## loc-4:germ-2 loc-4:germ-2
## loc-4:germ-3 loc-4:germ-3
## loc-4:germ-4 loc-4:germ-4
## loc-4:germ-5 loc-4:germ-5
## loc-4:germ-6 loc-4:germ-6descriptorsthe vector of descriptors cited knowing the threhold applyed when formated the data.
data_napping$descriptors## [1] "agréable" "aqueuse" "aromatique"
## [4] "douce" "équilibrée" "fade"
## [7] "farineuse" "fibreuse" "fondante"
## [10] "fruitée" "gouteuse" "juteuse"
## [13] "parfumée" "peau_épaisse" "raffraichissante"
## [16] "sans intérêt" "sucrée"4.4.4 Describe the data
First, you can describe the data regarding the descriptors for each germplasm for example.
descriptors = data_napping$descriptors
p_des = plot(data_napping, plot_type = "radar", vec_variables = descriptors, in_col = "sample")
p_des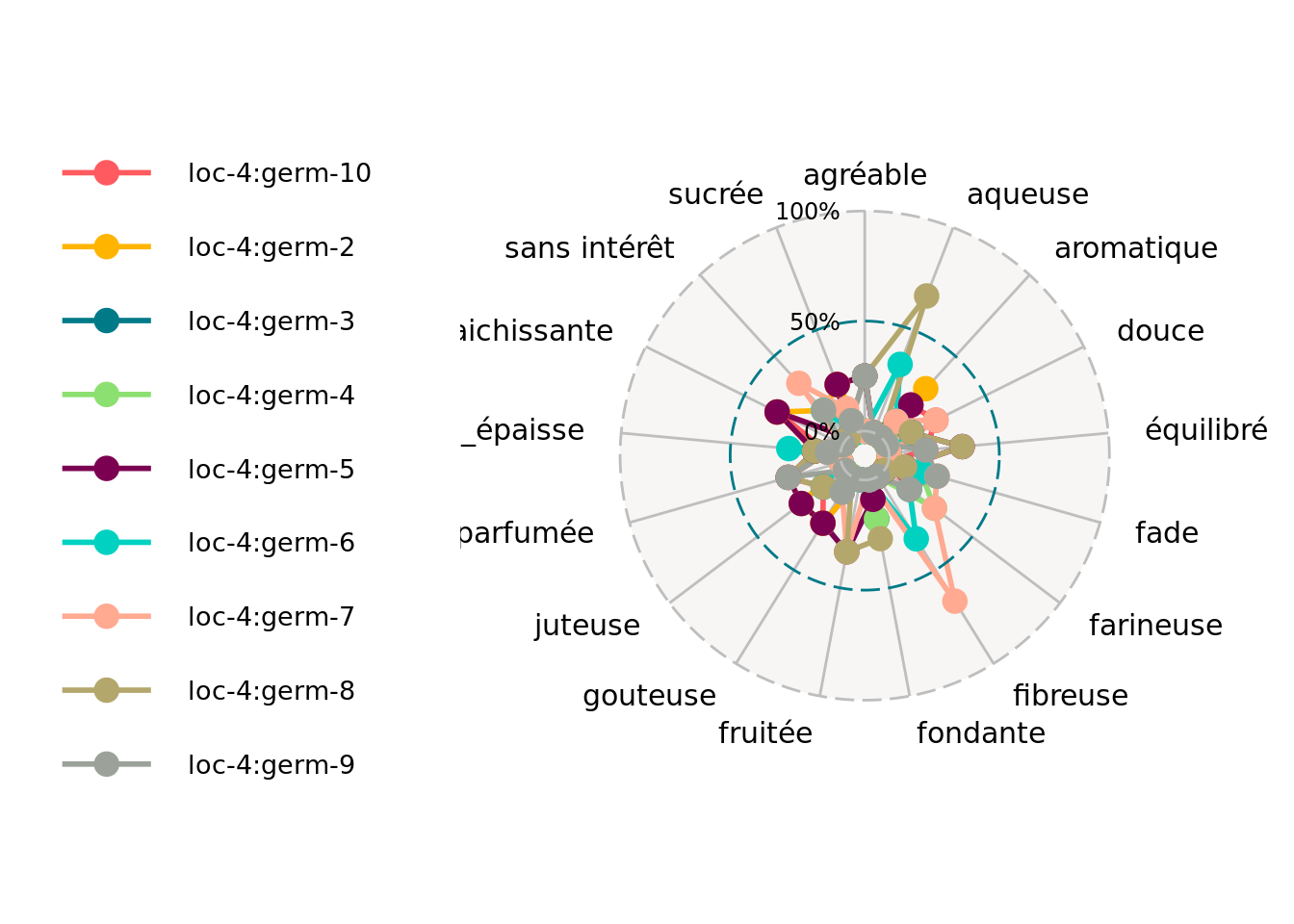
4.4.5 Run the model
To run the model on the dataset, used the function model_napping.
out_napping = model_napping(data_napping)out_napping is an object coming from FactoMineR::MFA
4.4.6 Check and visualize model outputs
The tests to check the model are explained in section 3.1.2.1.2.
4.4.6.1 Check the model
out_check_napping = check_model(out_napping)out_check_nappingis the same objet as out_napping
4.4.6.2 Visualize outputs
Once the computation is done, you can visualize the results with plot
p_out_check_napping = plot(out_check_napping)p_out_check_napping is a plot representing the variance caught by each dimension of the MFA
p_out_check_napping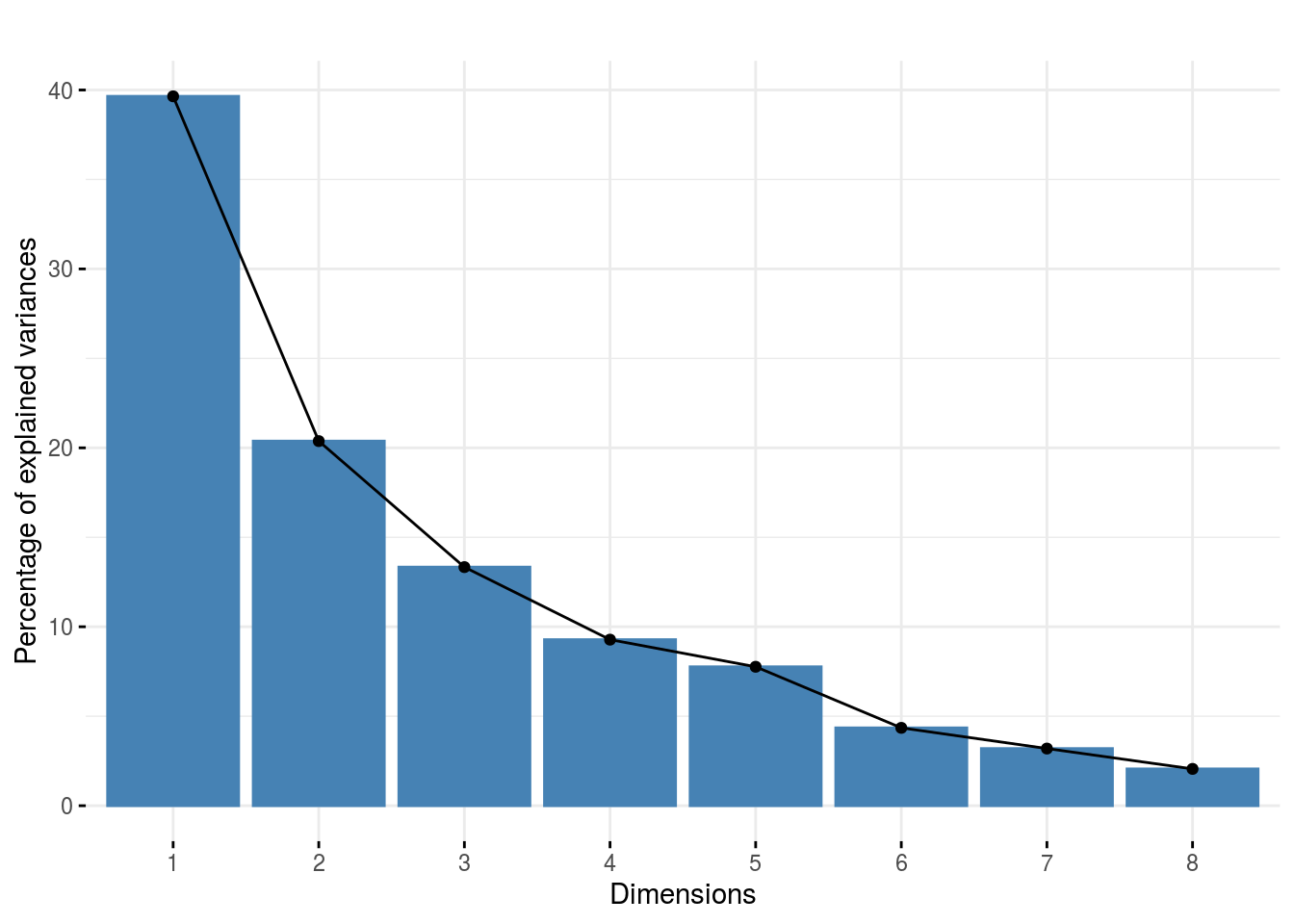
4.4.7 Get and visualize biplot
The biplot represents information about the percentages of total variation explained by the two axes. It has to be linked to the total variation caught by the interaction. If the total variation is small, then the biplot is useless. If the total variation is high enought, then the biplot is useful if the two first dimension represented catch enought variation (the more the better).
4.4.7.1 Get biplot
out_biplot_napping = biplot_data(out_check_napping)4.4.7.2 Visualize biplot
out_biplot_napping is the same objet as out_check_napping
p_out_biplot_napping = plot(out_biplot_napping)p_out_biplot_napping is a list of three elements:
- partial_axes
p_out_biplot_napping$partial_axes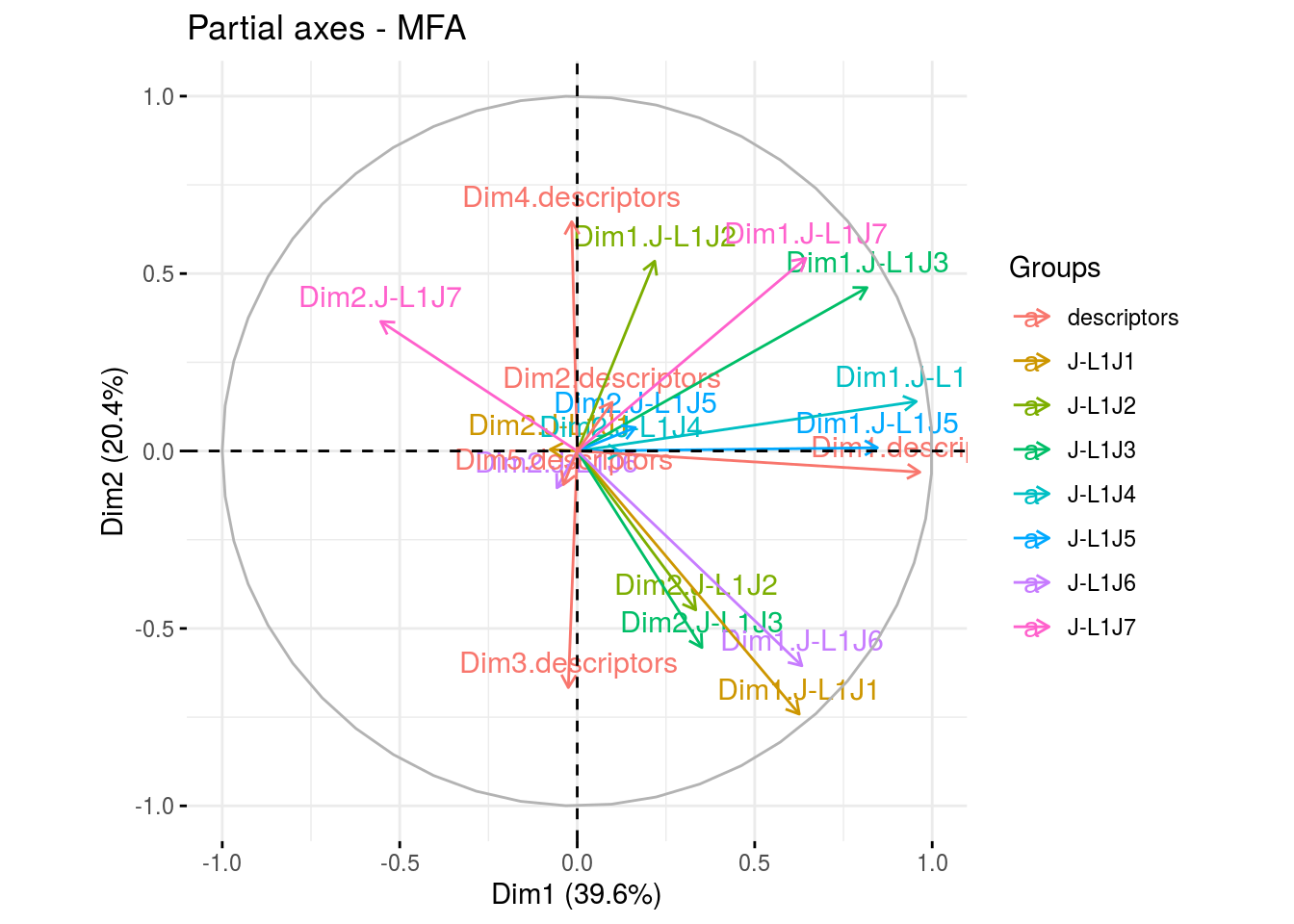 - ind
- ind
p_out_biplot_napping$ind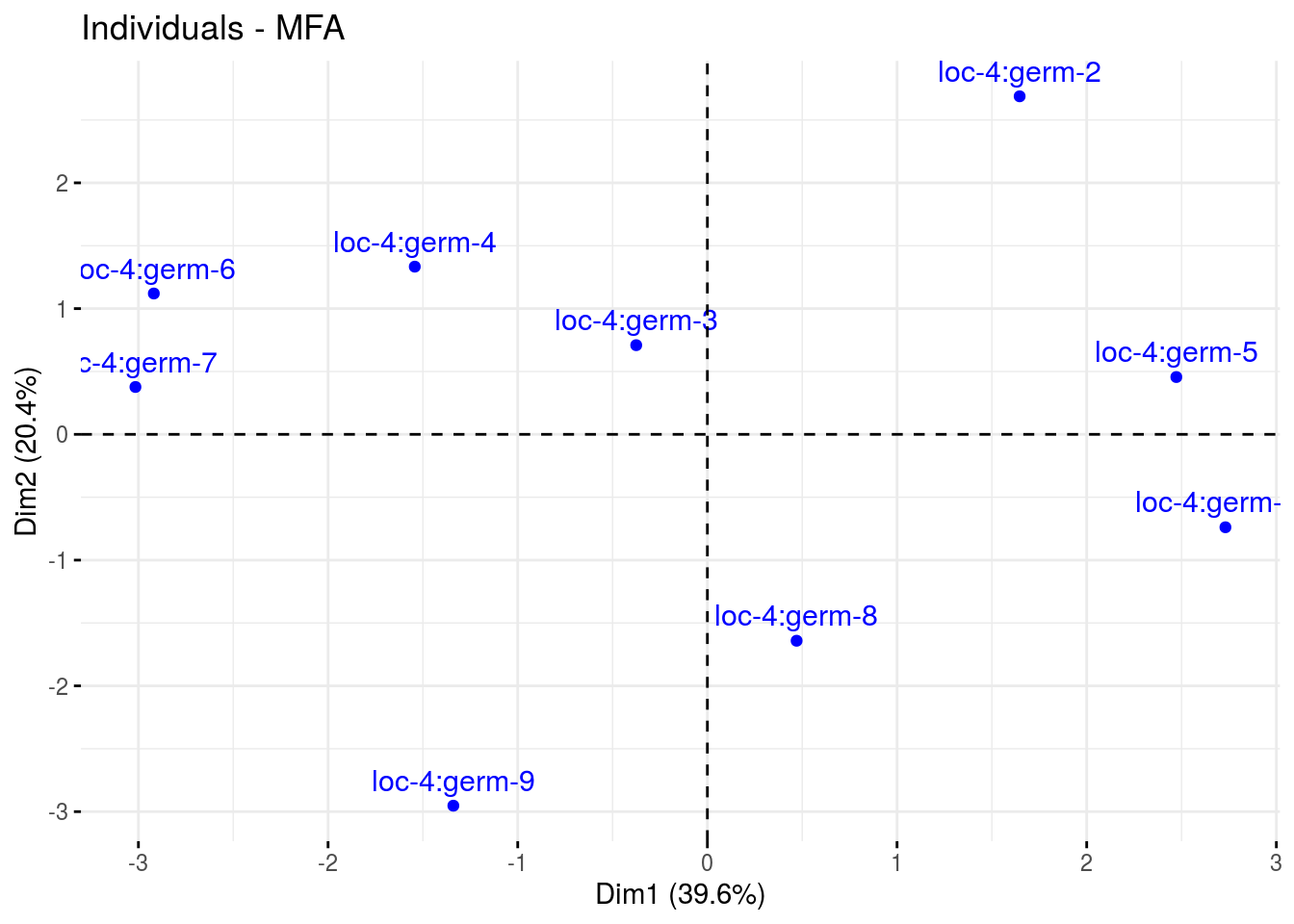 - var
- var
p_out_biplot_napping$var